
در این مطلب قصد داریم یکی از پروژه های جذاب هوش مصنوعی را انجام دهیم. در پروژه عنوان بندی تصاویر ما یک تصویر را به عنوان ورودی میدهیم و به به عنوان خروجی، یک جمله که شامل یک توصیف متنی از تصویر است را دریافت میکنیم؛
در مطالب قبلی با روند پردازش تصویر و متن ها آشنا شدیم، برای پردازش یک تصویر از شبکه های کانولوشنال (CNN) استفاده میکردیم و برای متون نیز از شبکه های عصبی بازگشتی (RNN) کمک میگرفتیم.
معماری شبکه ای که امروز با آن آشنا می شویم ترکیبی از شبکه های CNN و RNN است. ابتدا تصاویر توسط یک شبکه کانولوشنی پردازش می شوند و یک بردار ویژگی برای هر عکس بدست میآوریم. این بردار ویژگی به عنوان ورودی به یک شبکه برگشتی مانند LSTM داده میشود تا با مدل سازی زبان بتواند یک جمله در وصف عکس متناظر تولیدکند؛
معماری رمزگزار-رمزگشا (encoder-decoder)
معماری رمزگزار-رمزگشا یا encoder-decoder که در پاراگراف بالا توضیح دادیم و در تصویر زیر نیز قابل مشاهده است، امکان اجرا و آموزش یکجای مدل های ترکیبی را فراهم میکند.

معماری-رمزگزار-رمزگشا
کدنویسی پروژه با پایتون
در ادامه مراحل اجرایی یک پروژه Image Captioning را ملاحظه میکنید:
کدها و تصاویر استفاده شده در مطلب، از گیتهاب استادرضوی برداشته شده است. برای دریافت سورس کامل به این (لینک) مراجعه کنید؛
وارد کردن کابخانه های مورد نیاز:
pack_padded_sequence کار Padding برای یکسان سازی سایز جملات را انجام میدهد
[py]%reload_ext autoreload
%autoreload 2
%matplotlib inline
import os
import sys
import json
import pickle
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
from glob import glob
from IPython.display import display
import torch
import torch.nn as nn
import torch.optim as optim
from torch.nn.utils.rnn import pack_padded_sequence
import torchvision.transforms as transforms
import torchvision.models as models
from utils import *
from build_vocab import build_vocab
from data_loader import get_loader
# setup
use_gpu = torch.cuda.is_available()[/py]
توابع کمکی:
[py]def load_cnn_model(model_name, pretrained=True):
"Load and return a convolutional neural network."
assert model_name in [‘resnet18’, ‘resnet34’, ‘resnet50’, ‘resnet101’, ‘resnet152’]
return models.__dict__[model_name](pretrained)
def load_image(image_path, transform=None):
"Load an image and perform given transformations."
image = Image.open(image_path)
if transform is not None:
image = transform(image).unsqueeze(0)
return image[/py]
داده ها
برای این پروژه از دیتاست COCO استفاده میکنیم (لینک دیتاست)
البته چون قصد Persian Image Captioning داریم، برخی از داده ها ترجمه شده اند
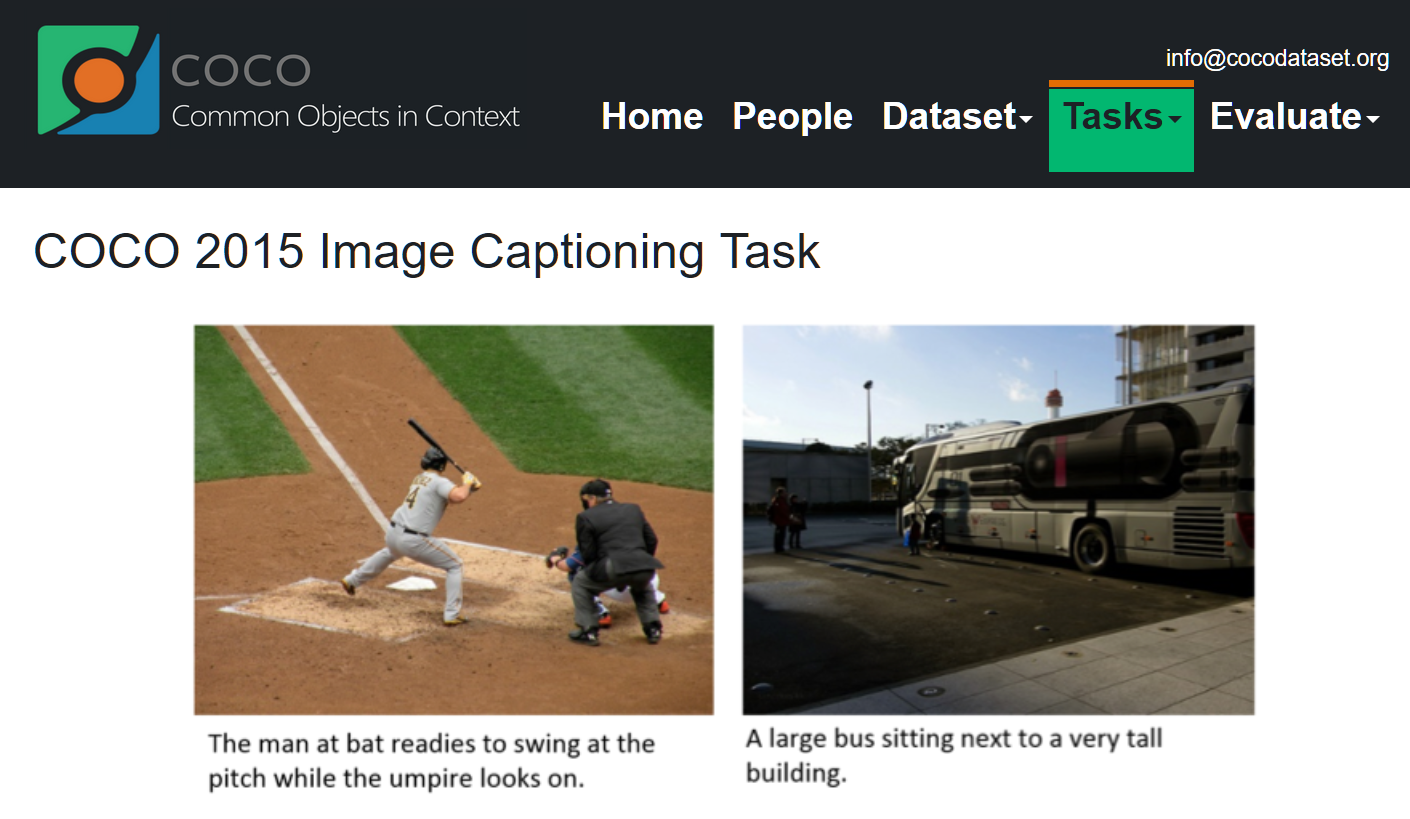
coco-dataset-caption
[py]dataset = load_json(‘data/fa_images_captions_train.json’)[/py]
ساخت واژگان
[py]DATA_DIR = ‘data’
captions_filename = f'{DATA_DIR}/fa_captions.txt’
vocab_filename = f'{DATA_DIR}/vocab.pkl’
if os.path.exists(vocab_filename):
vocab = pickle.load(open(vocab_filename, ‘rb’))
else:
vocab = build_vocab(captions_filename, min_count=3)
pickle.dump(vocab, open(vocab_filename, ‘wb’))[/py]
با اجرای کد کلمات بیشتر تکرار شده در دیتاست را مشاهده میکنید
[py]for i in range(20):
print("%s –> %d" %(vocab.idx2word[i], i))[/py]
Data loader
[py]images_dir = f'{DATA_DIR}/images’
captions_json = f'{DATA_DIR}/fa_images_captions_train.json’
image_size = 256
crop_size = 224
batch_size = 16
transform = transforms.Compose([
transforms.Resize(image_size),
transforms.RandomCrop(crop_size),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406),
(0.229, 0.224, 0.225))
])[/py]
[py]data_loader = get_loader(images_dir, captions_json, vocab,
transform, batch_size,
shuffle=True, num_workers=0)[/py]
[py]imgs, caps, lengths = next(iter(data_loader))
print(" ".join([str(id) for id in caps[0][1:-1]]))
print(" ".join([vocab.idx2word[id] for id in caps[0][1:-1]]))[/py]
ساخت مدل
همانطور که توضیح دادیم، برای این پروژه به معماری رمزگزار-رمزگشا نیاز داریم و مدل ما از دو بخش پیوسته به هم تشکیل میشود.
ابتدا برای پردازش تصویر یک شبکه کانولوشنال ایجاد میکنیم
1. Encoder (CNN)
[py]class EncoderCNN(nn.Module):
def __init__(self, model_name, embed_size):
super(EncoderCNN, self).__init__()
# load cnn and remove last layer
cnn = load_cnn_model(model_name)
modules = list(cnn.children())[:-1] # remove last layer
self.cnn = nn.Sequential(*modules)
self.linear = nn.Linear(cnn.fc.in_features, embed_size)
self.bn = nn.BatchNorm1d(embed_size, momentum=0.01)
self.init_weights()
def init_weights(self):
self.linear.weight.data.normal_(0, 0.02)
self.linear.bias.data.fill_(0)
def forward(self, x):
x = self.cnn(x) # extract features from input image
x = Variable(x.data)
x = x.view(x.size(0), -1)
x = self.linear(x)
x = self.bn(x)
return x
def fine_tune(self, requires_grad=True):
for param in self.cnn.layer4.parameters():
param.requires_grad = requires_grad[/py]
2. Decoder (LSTM)
[py]class DecoderLSTM(nn.Module):
def __init__(self, vocab_size, embed_size, hidden_size, num_layers, dropout, tie_weights):
super(DecoderLSTM, self).__init__()
if tie_weights:
embed_size = hidden_size
self.embedding = nn.Embedding(vocab_size, embed_size)
self.lstm = nn.LSTM(embed_size, hidden_size, num_layers, batch_first=True, dropout=0.35)
self.fc = nn.Linear(hidden_size, vocab_size)
self.dropout = nn.Dropout(p=dropout)
if tie_weights:
# share weights between embedding and classification layer
self.fc.weight = self.embedding.weight
self.init_weights()
def init_weights(self):
self.embedding.weight.data.uniform_(-0.1, 0.1)
self.fc.weight.data.uniform_(-0.1, 0.1)
self.fc.bias.data.fill_(0)
def forward(self, features, captions, lengths):
x = self.embedding(captions)
x = torch.cat([features.unsqueeze(1), x], dim=1)
x = self.dropout(x)
x = pack_padded_sequence(x, lengths, batch_first=True)
x, _ = self.lstm(x)
x = self.dropout(x[0])
x = self.fc(x)
return x
def sample(self, features, states=None):
"""Samples captions for given image features (Greedy search)."""
sampled_ids = []
inputs = features.unsqueeze(1)
for i in range(20): # maximum sampling length
hiddens, states = self.lstm(inputs, states) # (batch_size, 1, hidden_size),
outputs = self.fc(hiddens.squeeze(1)) # (batch_size, vocab_size)
token_id = outputs.max(1)[1]
sampled_ids += [token_id]
inputs = self.embedding(token_id)
inputs = inputs.unsqueeze(1) # (batch_size, 1, embed_size)
sampled_ids = torch.cat(sampled_ids, 0) # (batch_size, 20)
return sampled_ids.squeeze()[/py]
معماری رمزگزار-رمزگشا (encoder-decoder)
[py]class EncoderDecoder(nn.Module):
def __init__(self, cnn_name, vocab_size, embed_size, hidden_size, num_layers, dropout, tie_weights):
super(EncoderDecoder, self).__init__()
if tie_weights:
embed_size = hidden_size
self.encoder = EncoderCNN(cnn_name, embed_size)
self.decoder = DecoderLSTM(vocab_size, embed_size, hidden_size, num_layers, dropout, tie_weights)
# create output folder to save weights
self.save_path = f'{cnn_name}-{embed_size}-{hidden_size}-{num_layers}’
if not os.path.exists(self.save_path):
os.mkdir(self.save_path)
def forward(self, images, captions, lengths):
features = self.encoder(images)
outputs = self.decoder(features, captions, lengths)
return outputs
def save(self, epoch, loss):
torch.save({‘encoder’: self.encoder.state_dict(),
‘decoder’: self.decoder.state_dict()}, f'{self.save_path}/{epoch}-{loss:.2f}.pth’)
def load(self, epoch):
model_path = glob(f'{self.save_path}/{epoch}-*.pth’)[-1]
try:
d = torch.load(model_path)
self.encoder.load_state_dict(d[‘encoder’])
self.decoder.load_state_dict(d[‘decoder’])
except:
print(‘Invalid epoch number <{}>, the model does not exist!’.format(epoch))[/py]
پارامترها
[py]# model hyper-parameters
cnn_name = ‘resnet50’
embed_size = 512
hidden_size = 512
num_layers = 2
tie_weights = True
# training hyper-parameters
start_epoch = 0
num_epochs = 20
learning_rate = 0.001[/py]
Training آموزش مدل
[py]def train_epoch(model, train_dl, criterion, optimizer, scheduler, epoch, last_epoch):
model.encoder.train()
model.decoder.train()
scheduler.step()
total_steps = len(train_dl)
epoch_loss = 0.0
for i, (images, captions, lengths) in enumerate(train_dl):
images, captions = to_var(images), to_var(captions)
targets = pack_padded_sequence(captions, lengths, batch_first=True)[0]
# forward step
outputs = model(images, captions, lengths)
loss = criterion(outputs, targets)
epoch_loss = (epoch_loss * i + loss.data[0]) / (i + 1)
# backward step
model.encoder.zero_grad()
model.decoder.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm(model.decoder.parameters(), 5.0)
optimizer.step()
# report log info
sys.stdout.flush()
sys.stdout.write(‘\rEpoch [%2d/%2d], Step [%3d/%3d], Loss = %.4f, Perplexity = %.4f ‘
% (epoch+1, last_epoch, i+1, total_steps, epoch_loss, np.exp(epoch_loss)))
print()
return epoch_loss
def train(model, train_dl, criterion, optimizer, scheduler, start_epoch=0, num_epochs=10):
last_epoch = start_epoch + num_epochs
for epoch in range(start_epoch, last_epoch):
# train step
trn_loss = train_epoch(model, data_loader, criterion, optimizer, scheduler, epoch, last_epoch)
# save model
model.save(epoch, trn_loss)[/py]
[py]model = EncoderDecoder(cnn_name, len(vocab), embed_size, hidden_size, num_layers, 0.3, tie_weights)
if use_gpu:
model = model.cuda()[/py]
تعریف تابع هزینه و بهینه سازی (Loss and optimizer)
[py]# loss function
criterion = nn.CrossEntropyLoss()
if use_gpu:
criterion = criterion.cuda()
# list of parameters which will be updated
params = list(model.decoder.parameters())
params += list(model.encoder.linear.parameters())
params += list(model.encoder.bn.parameters())
# optimizer
optimizer = torch.optim.RMSprop(params, lr=learning_rate)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.97)[/py]
و با اجرای کد زیر مدل شروع به آموزش دیدن میکنید که مقداری زمانبر است و به قدرت سیستم عامل استفاده شده بستگی دارد:
[py]train(model, data_loader, criterion, optimizer, scheduler, start_epoch, num_epochs)[/py]
نمونه برداری: ساخت توضیح برای تصاویر
بعد از آموزش مدل، حال نوبت تست کردن و ساخت کپشن برای تصاویر انتخابی است
[py]from PIL import Image
val_transform = transforms.Compose([
transforms.Resize(image_size),
transforms.CenterCrop(crop_size),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406),
(0.229, 0.224, 0.225))
])[/py]
[py]def generate_caption(model, img_filenames):
model.encoder.eval()
model.decoder.eval()
captions = []
for img_filename in img_filenames:
# prepare test image
image = load_image(img_filename, val_transform)
image_tensor = to_var(image, volatile=True)
# Generate features from image
feature = model.encoder(image_tensor)
# Generate caption from image
sampled_ids = model.decoder.sample(feature)
sampled_ids = sampled_ids.cpu().data.numpy()
# decode word ids to words
sampled_caption = []
for word_id in sampled_ids:
word = vocab.idx2word[word_id]
if word == ‘<EOS>’: break
sampled_caption.append(word)
caption = " ".join(sampled_caption[1:])
captions.append((img_filename, caption))
return captions[/py]
[py]img_filenames = glob(‘data/images/*.jpg’)[:10]
captions = generate_caption(model, img_filenames)
for img, caption in captions:
display(show_persian_image_and_caption(caption, img))[/py]
[py]img_filenames = glob(‘./data/im2txt/*.jpg’)[:10]
captions = generate_caption(model, img_filenames)
for img, caption in captions:
display(show_persian_image_and_caption(caption, img))[/py]
کد های بالا حدود ده تصویر را به همراه توضیح ساخته شده توسط مدل، به ما نمایش میدهند؛
روش های بهینه سازی مدل
- استفاده از دیتاست بزرگتر و داده های بیشتر
- استفاده از بردار واژگان از قبل آموزش دیده
- استفاده از شبکه برگشتی دوسویه BiLSTM
- افزایش عمق مدل
- و…



